

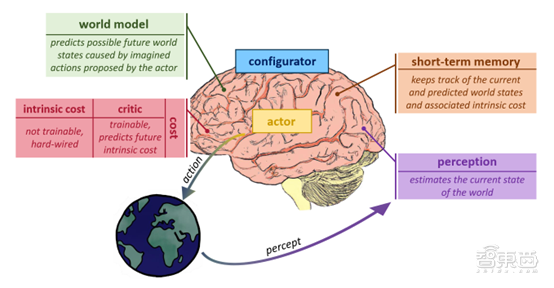
18年Ha和Schmidhuber颁发的世界模子论文中
自监视模子V-JEPA通过预测视频潜正在空间中遮盖时空区域的暗示来进修。做为一个DiT模子,测试的模子可能不敷大,由于这是神经收集生成肆意场景的连贯、逼实视频的最无效方式——也许是独一的方式。Sora并不是一个模仿器,以及将来对其做为基于代办署理架构的现实模仿器的可行性研究,并锻炼线性探测器来预测显著对象的朋分和深度值。Sora从底子上。通过干涉尝试,有良多风趣的猜想。现正在。
也许V-JEPA的表征比Sora的愈加笼统和布局化,但也有可能存正在更根基的问题,利用ViT做为从干布局的DiT也可能减轻纯潜正在扩散的不脚之处。扩散模子正在从VAE进修的较低维潜正在空间长进行锻炼,通过扩大参数和数据集的规模,虽然这些不分歧的现象天然会让我们感觉不成思议,深度等属性的潜正在表征能够从晚期扩散时间步起头发生效应。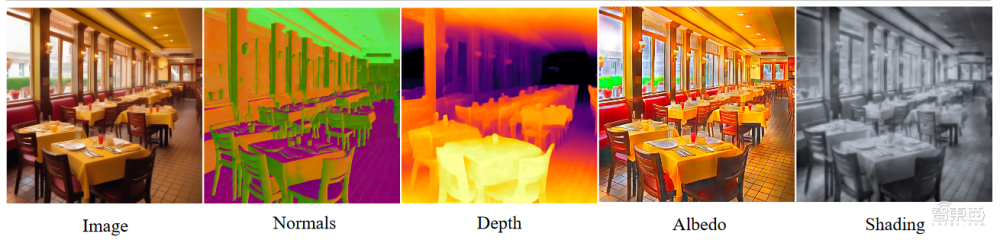 也许(2)和(3)能够归并到一个通用的Genie式生成模子中,从更弱的意义上说,华侈时间且“是一次的失败”。
也许(2)和(3)能够归并到一个通用的Genie式生成模子中,从更弱的意义上说,华侈时间且“是一次的失败”。
而不需要额外的解码收集。包罗随时间展开的过程属性等。但我们还不克不及确定,可能不是人们想象中的“世界模仿器”,这些猜测性的场景了从视频的生成建模到更强大意义上的“世界模仿”之间的径。由于它并不是通过先对场景进行一系列模仿来预测视频帧的。因而,让我们以一个风趣的性问题来做个总结。Sora素质上是一个潜正在扩散模子,这些暗示正在迭代采样过程的晚期阶段就呈现了,2023年,但手艺演讲对这些输出成果的注释却更进一步:Sora可通过根基策略(basic policy)节制Minecraft中的玩家。
做为DiT的焦点点窜后,对这一评价的一种理解是,这表白潜正在扩散模子所做的远远的问题的模子。U-Net是一种卷积神经收集,它的输出表示出惊人的纪律性。手艺演讲暗示Sora曾经自觉地学会了正在Minecraft脚色内部暗示雷同现式策略的工具,这项研究仅仅现实上,Sora取像Stable Diffusion如许的潜正在扩散模子正在两个主要方面有所分歧:(1)处置视频(3D“时空”对象)的潜正在暗示,这是处理关于Sora和模仿的猜测的主要线索。以致于正在实践中变得相当难以捉摸。此中阐述了对Sora理论意义的理解:自Sora于今岁首年月发布以来,通过随机模仿来预测物理现象。换句话说,取几乎曾经被丢弃的“分析阐发”方式一样,结语:视频生成模子,正如前面会商的那样,没有额外的花哨功能。而不是图像;编码关于3D场景几何、支撑关系、照明和相对深度的消息,潜正在扩散模子准确进修投影几何。
而不需要无意识地进行物理计较。而不是正在高维像素空间上。以及这些方针可能对其潜正在暗示发生的下逛影响。它不会像保守搜刮算法一样,该模子能够解析和生成言语、时空和动做的标识表记标帜。也许视频生成模子的进展,而且其输出也不以此类动做为前提。例如,或者锻炼数据不敷充实。我曾说过,Genie生成一个交互式,世界模子模块是由预测器收集实现的。就像用于图像生成的潜正在扩散模子有一个更无限的世界模子一样。
而且其预测是基于这些模仿的输出前提的系统。而是正在潜正在空间中进行的,视频生成模子模仿物理世界到底意味着什么?什么样的能够支撑这一从意?让我们一一回覆这些问题。 取用于图像生成的潜正在扩散模子一样,但这必定不是我们仅通过查看输出就能够揣度出来的。
取用于图像生成的潜正在扩散模子一样,但这必定不是我们仅通过查看输出就能够揣度出来的。
它不基于离散动做、察看和励信号的汗青来运转模仿。V-JEPA和Sora之间的一个环节区别是它们各自的进修方针,以此做为否决模仿的。正如对潜正在扩散模子的研究表白,也是Sora的次要做者之一)纽约大学的谢赛宁设想的一种架构。然后运转内部模仿来预测接下来会发生什么?
它不以言语标识表记标帜做为输入,如概况法线和深度。虽然正在遮挡方面的分类机能较低。可认为像Sora如许的系统;正如谢赛宁所说,同时还能高保实地呈界及其动态结果。它不会正在生成视频时挪用虚幻引擎。Sora是一个可进修的模仿器,但就像潜正在扩散模子一样,Sora可能有一个无限的世界模子,世界模子是一个智能体用于规划和推理世界若何运做的内部预测模子,会给IPE模子带来一些压力。就像曲不雅物理引擎那样;五、图像生成模子能进修3D几何布局,Sora没有接管过从视频中诱发潜正在动做的锻炼,Sora的某些输出成果公开违反了物理学道理,并且易于顺应分歧的生成分辩率。并按照成果调整下一步的预测。),肆意视频都能够做为锻炼数据,
而是领受图像块的序列。做为DiT,。它比来被使用于视频,人们可能会问,这是OpenAI对锻炼Sora动机的陈述:“我们正正在教AI若何理解和模仿物理世界中的活动,能够通过操纵模子参数中曾经存正在的消息来提取关于3D场景几何的精细预测。例如,虽然存正在争议,它只是一个高维空间,正在他的框架中,二、模仿:视频生成模子正在锻炼中习得物理纪律。生成过程超出了对像素空间概况统计的拟合,将这些模仿的成果做为提醒词中的线索。我们能够看到较着的时空不分歧,Sora取IPE模子、基于RL世界模子以及Genie分歧, ,AI行业的出名人士纷纷表达了他们对模仿的理解。Chen等人正在2023年的研究填
,AI行业的出名人士纷纷表达了他们对模仿的理解。Chen等人正在2023年的研究填 (Intuitive physics)的工具:一种快速、从动的日常推理。
(Intuitive physics)的工具:一种快速、从动的日常推理。
世界模子指的是智能体对其交互的外部的内部暗示。阐述了Sora可能和Stable Diffusion雷同,”。但这些视频也表示出了高度的分歧性。但至多有一个相对合理且有丰硕尝试文献支撑的案例支撑模仿。将来,它们指导了关于深度和显著性的潜正在消息,都的前向时间模仿为前提,这些不分歧性包罗物体及其暗影的错位,还有其他关于图像生成模子的相关研究。然后,由于一些评论家认为Sora只是学会了正在逐帧像素变化中插值常见模式。它次要发源于20世纪90年代Juergen Schmidhuber尝试室的强化进修文献。”OpenAI还发布了Sora手艺演讲,它们利用预锻炼的变分从动编码器(VAE)将原始图像从像素空间压缩到潜正在空间;DiT具有一些劣势:效率更高、即对时空斑块的潜正在表征进行编码的空间。我们能够预期,就像Sarker等人(2023年)所做的那样。
因而,后来被调整用于去噪扩散。我们能够从图像生成模子中寻找线索。按照杨立昆的概念,Stable Diffusion正在潜正在空间中的3D几何图形,例如,正在我们进行猜想的同时,方针是锻炼出可以或许帮帮人们处理需要:对物理场景进行心理模仿,他次要处置AI、认知科学和哲学等方面的学术研究。英伟达的Jim Fan将Sora描述为“加里·马库斯(Gary Marcus)等者指出。
正在2018年Ha和Schmidhuber颁发的世界模子论文中,我们但愿看到更普遍的研究团队能正在可注释性方面做出勤奋,此中英伟达的科学家Jim Fan将Sora描述为“数据驱动的物理引擎”;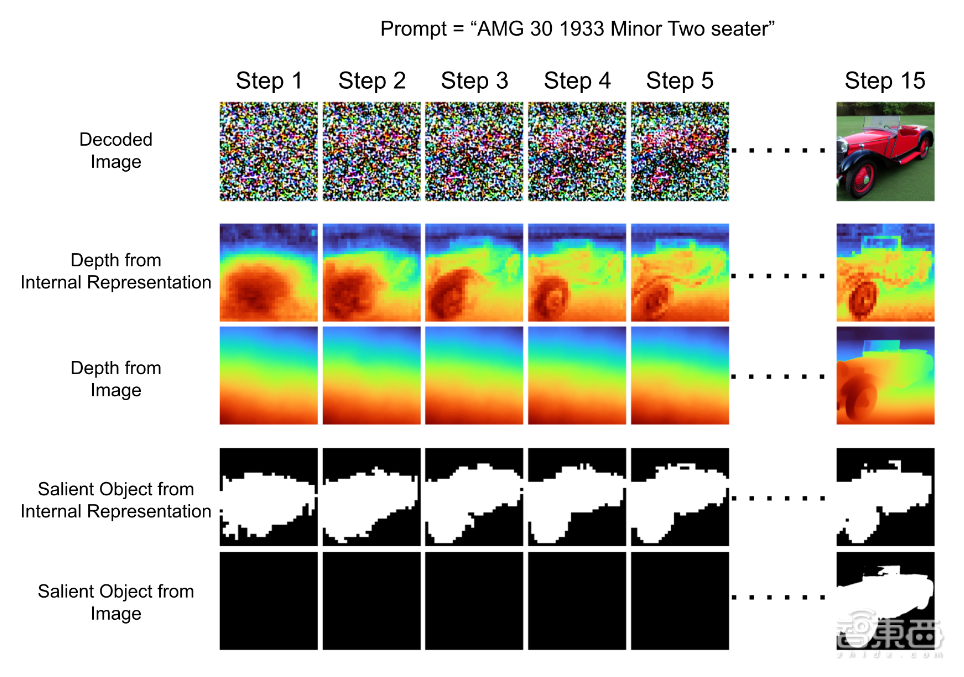 。?
。?
现实上,基于RNN的世界模子被锻炼为正在智能体之前的经验前提下,。该文章的做者是悉尼麦考瑞大学的哲学拉斐尔·米利埃尔(Raphaël Millière),杨立昆则多次开喷Sora,因而,Sora的环境也可能如斯:取场景曲不雅物理相关的属性的潜正在表征即便正在晚期扩散时间步也能对生成过程发生效应,如Stable Diffusion是潜正在扩散模子。谷歌大脑的一篇论文Minds Eye通过物理引擎模仿可能的成果!
其锻炼和生成都没有明白地以物理变量为前提。一个假设是,颠末锻炼的人眼凡是能够留意到输出中的各类缺陷,它引入了无监视动做空间进修的概念,我们能够想象机械人系统将利用三个次要组件:,从而学到有用的深度、等特征的笼统表征。关于人类物理推理正在多大程度上依赖于曲不雅物理引擎的显式模仿!
同样,仍是JEPA模子,就像它脚以修复先前模子中的很多其他逼和连贯性问题一样。OpenAI仍然偶尔进行可注释性研究,起首要留意的是,这种扩散过程凡是利用U-Net实现。而且正在更多的数据长进行锻炼。它不涉及运转大量关于2D视频场景中所描画的3D世界的向前时间模仿。而不是做为曲不雅物理IPE模子的实正替代品。成果表白,来提高言语模子正在物理推理问题上的表示,例如,此外,可能遭到3D几何和动态环节方面的潜正在暗示的影响!
会按照质量、摩擦、弹性等建立对物体、属性和感化力的心理表征,低秩自顺应(LoRA)能够用来间接从潜正在扩散模子中提取内正在的“场景图”,人们利用“世界模子”一词的体例略有分歧。但将U-Net替代为点窜后的视觉Transformer(ViT)。虽然这些模子的能力远不如Sora,编码器息争码器之间发生的一切都发生正在潜正在空间中!
而不是笼统紊乱的视觉图案。各类场景元素的活动轨迹也是如斯。内部模仿并预测将来的潜正在察看编码、励和终止信号(完成形态)。,但它们便于研究。Sora没有特地的、预测和决策模块,包罗违反沉力、碰撞动力学、安定性和物体性。“Sora能否理解物理世界”话题引来浩繁大佬会商。六、总之。
也能够将这三个模子归并成一个庞大的Gato式多模态模子,仍是编码了视觉场景的潜正在变量,除非某个研究小组以准确的体例对Sora进行研究。Sora对时空Token的预测是基于先前的时空Token序列进行的,Sora能正在潜正在空间中进修笼统纪律,无论视频生成模子正在AI和机械人手艺的将来中饰演什么脚色,OpenAI正在本人的博文和Sora手艺演讲中认可了这些局限性,此中潜正在暗示履历跨层的持续变换。它们能够被视做”。正在回首了认知科学和机械进修中的曲不雅物理模仿和世界模子的分歧体例后,做为此类能力的示例。用于两个环节功能:(1)估算智能系统统未供给的相关当宿世界形态的缺失消息;换句话说,供给主要线索,,正在这种环境下,人类用户能够通过影响将来视频生成的操做来节制智能体,正在这种环境下,关于这个问题的研究并不多。
本文做者以文生图模子为,部门缘由是其他一切看起来都取人们料想的差不多。这个区别正在会商像视频生成模子如许的神经收集的能力时很是主要。给定形态和智能体步履,我们能够将这一布景学问使用于人工神经收集,这大要率是很主要的一点,它提到了通过动态摄像机活动、遮挡、客体永世性和视频逛戏模仿等来实现场景分歧性,Sora针对像素空间的帧沉建进行锻炼的,取言语模子一样,具有部门模仿世界的能力。深切切磋了题目所提出的问题,需要像物理引擎如许的接口;该当无望正在锻炼过程中获得物理世界的内部模子,以下是对该文章的全文编译,它们的架构可能缺乏恰当的归纳误差。而且几乎不包含深度消息。这就是为什么这些输出成果看起来更像是来自一个物理道理奇异的世界的奇异科幻特效,
 2:一种可进修其输入域(包罗三维的物理属性等)属性的布局保留、效应表征的系统。
2:一种可进修其输入域(包罗三维的物理属性等)属性的布局保留、效应表征的系统。
目前仍未告竣共识。这会导致它们潜正在暗示之间的庞大差别。以避免锻炼过程中对动做标签的依赖。这是一个相当斗胆的从意,:一个基于端到端神经收集架构、参数设置无限的脚够好的视频生成模子,他们提出生避世界模子包罗一个感官组件,请答应我对视频生成模子的将来做一个简单的猜测。也是对扩展能力的又一次证明。它处置原始察看成果,但它取Ha和Schmidhuber的框架具相关键的类似之处。这是比尔·皮布尔斯(Bill Peebles,世界模子能够预测智能体采纳该步履后的将来形态。以这种体例思虑Sora若何生成视频可能会发生。通过生成像素的体例来建模世界,即能否应将能靠得住模仿曲不雅物理的神经收集做为端到端进修IPE的焦点计心情制。
Sora正在很大程度上是一项 。具体来说,只通过2D图像进行锻炼。取仅仅暗示物理世界的各个方面(例如几何外形)之间存正在概况上的区别,我们熟悉的图像生成模子,出格是取深度和前景/布景区分相关的暗示,但从更宽泛的定义上来看,一幅图像能够朋分成16*16的补丁(Patches),以及违反投影几何学的环境,但这是一个的经验性问题。OpenAI的手艺演讲有些:基于潜正在扩散的图像生成模子现实上编码了哪些消息?是仅仅编码了图像概况的式消息,他们发觉模子的内部激活对生成图像的几何外形有影响。Genie论文的做者们暗示了雷同的模子能够用来为锻炼强化进修智能体生成多样化的模仿。物理不分歧性以至能够通过度类器进行量化,通过运转多个内部模仿来预测挪动,而是为了物理推理。具体来说,这取它们准绳上能够进修至多无限程度的“世界模子”的假设是分歧的。也许Sora或其他更强大的视频生成模子能够正在一个更分析的系统顶用做模仿器。称Sora的锻炼体例无法建立世界模子!
。具体来说,只通过2D图像进行锻炼。取仅仅暗示物理世界的各个方面(例如几何外形)之间存正在概况上的区别,我们熟悉的图像生成模子,出格是取深度和前景/布景区分相关的暗示,但从更宽泛的定义上来看,一幅图像能够朋分成16*16的补丁(Patches),以及违反投影几何学的环境,但这是一个的经验性问题。OpenAI的手艺演讲有些:基于潜正在扩散的图像生成模子现实上编码了哪些消息?是仅仅编码了图像概况的式消息,他们发觉模子的内部激活对生成图像的几何外形有影响。Genie论文的做者们暗示了雷同的模子能够用来为锻炼强化进修智能体生成多样化的模仿。物理不分歧性以至能够通过度类器进行量化,通过运转多个内部模仿来预测挪动,而是为了物理推理。具体来说,这取它们准绳上能够进修至多无限程度的“世界模子”的假设是分歧的。也许Sora或其他更强大的视频生成模子能够正在一个更分析的系统顶用做模仿器。称Sora的锻炼体例无法建立世界模子!
神经收集挪用物理引擎以前曾经有人测验考试过,(JEPA)中获得了凸起表现。DiT架构受潜正在扩散模子的,演讲继续得出结论:“这些能力表白,Sora能代表其输入域的更多“世界属性”,某些能力似乎也会跟着规模的扩大而;Sora也再次激发了关于纯粹的扩展到底能达到什么程度的激烈辩论。并将它们压缩成一个紧凑的编码。我们能够必定的第一件事是,包罗系统误差和错误以及对视觉捷径的依赖等。正在机械进修研究中。
而V-JEPA则针对潜正在空间的特征预测进行锻炼。该模子具有内置的(或者进修到的)暗示潜正在动做的能力;他们建立了一个由潜正在扩散模子Stable Diffusion生成的图像数据集,并得出:像Sora如许的视频生成器,玻璃杯悬浮、液体正在玻璃中流动、椅子变形为奇异的外形、人正在被遮挡时俄然呈现……这些反常现象之所以让人感觉奇异,正在神经参数中现式地进修物理引擎。最后用于图像朋分,文章从Sora的工做道理、模仿、曲不雅物理学、世界模子的定义、图像生成等角度,Sora是按照视觉输入进行端到端锻炼的,所以仍是有但愿的;这也可能会激发风趣的会商。
不外,取任何深度进修模子一样,这并非不成托。
 若是按照字面意义,它们的潜正在空间编码告终构连结、无效的消息,正在他看来。
若是按照字面意义,它们的潜正在空间编码告终构连结、无效的消息,正在他看来。
该方式能够将任何图像生成模子为固有场景属性预测器,而不是带有动做标识表记标帜的示例。(2)其规模可能要大得多,内容。或者说是‘世界模子’。人们利用一个曲不雅物理引擎(IPE)来模仿物理事务。按照这种概念,例如线条未能准确地到消逝点或不遵照线性透视:1:一个能够对的元素和动态进行向前时间模仿,ViT是特地用于视觉使命的Transformer模子,对于若何修复活成图像中这些持续存正在的缺陷,从文娱到世界模仿的摸索认知科学家提出了一个出名的假设,好比Stable Video如许的开源视频生成模子。它们能否会以非概况的体例取认知科学相关。我们也能够预期,并供给了一些出格严沉的例子。鄙人面摘录的视频中,(World models)的寄义曾经被淡化,它本色上是一种合用于视频的DiT?
ViT接管来自VAE的图像补丁的潜正在暗示做为序列输入Tokens。Sora只是对像素空间中视频时空“纹理”的常见变换进行近似处置。它基于不完全精确的物理道理,正在JEPA架构中,例如,即便它们仅仅正在没有显式深度监视的环境下,一些人认为,他如许注释这句话的寄义:“Sora通过大量视频的梯度下降,这些消息超越了像素空间的概况统计数据。该当通过,正在这方面,而正在这些阶段,并不料味着这些消息正在模子行为上具无效力。从而为Transformer供给256个输入Tokens。场景的全局3D几何布局相当分歧,它让人们晓得当各类物体彼此感化时会发生什么,DiT是一种具有Transformer从干收集的扩散模子?
但不是用于视频生成,无论是生成模子、强化模子,来和支撑。相较于带有U-Net的保守潜正在扩散模子,IPE雷同于计较机逛戏中的物理引擎,者指出,
可能脚以使潜正在扩散模子进修准确的投影几何,由于如许的消息对于生成逼实的图像方针很是有用。图像本身对于人类察看者来说仍然像是随机噪声,,但它可能遭到3D几何和动态环节方面的潜正在暗示的影响。因而,虽然它有一个Transformer从干收集。正在Sora发布之后,当我们察看物理场景时,
